SQL က Relational စစ်သလား?

တက္ကသိုလ်မှာတုန်းက SQL က “Relational Database” အစစ်မဟုတ်ပါဘူးဆိုတဲ့ စာလေးသွားဖတ်မိတယ်။ နောက်တော့ အဲဒီစာပိုဒ်လေးကိုပဲ presentation လုပ်ဖို့ အလှည့်ကျတယ်။ သင်ရိုးစာအုပ်မှာက တစ်ပိုဒ်ပဲပါပြီး ဘယ်လိုကွဲပြားတယ်ဆိုတာ ကို သေချာ မရေးထားဘူး။ ဒါနဲ့ ကိုယ်တွေလည်း အင်တာနက်ပေါ်တက်ရှာရတော့တာပေါ့။ ရှာရင်းနဲ့ CJ Date ရေးထားတဲ့ “SQL and Relational Theory” ဆိုတဲ့စာအုပ်လေးသွားတွေ့တယ်။ စာအုပ်ကတော်တော်လေး ကိုယ့်ကို SQL အခြေခံထားတဲ့ သဘောတရားတွေကို နားလည်သွားစေတယ်။ ပြီးတော့ SQL ရေးရတာမုန်းတဲ့ ကိုယ်တွေတောင် SQL က တစ်ကယ်ရေးတတ်ရင် ဘယ်လောက်ထိ စွမ်းအားကြီးတဲ့ လက်နက်တစ်ခုဖြစ်လာနိုင်တယ်ဆိုတာ နားလည်သွားတယ်။ စာအုပ်လေးပြန်ဖတ်ဖြစ်တာနဲ့၊ ကောက်နှုတ်ထားတာလေးတွေ ဝေမျှမယ်ဆိုပြီး ဒီ blog လေးရေးဖြစ်သွားတယ်။
Relational Theory
Relational Database အခြေခံတဲ့ Relational Model ကို ၁၉၆၉ မှာ E. F. Codd ကတင်ပြခဲ့တယ်။ ဒီ Model ကို အခြေခံပြီး SQL ကနောက်တော့မှ ပေါ်လာတာဖြစ်တယ်။ ဘာလို့ သီအိုရီတွေကအရေးကြီးလဲဆိုတော့ သီအိုရီဆိုတဲ့အရာက နည်းပညာတွေဘယ်လောက်ပဲပြောင်းပြောင်း အခြေခံ principle တွေက ပြောင်းလေ့မရှိဘူး။ လောင်စာကားဖြစ်ဖြစ်၊ လျှပ်စစ်ကားဖြစ်ဖြစ် v = d/t ဆိုတဲ့ အလျင်ကိုတွက်တဲ့ ဖော်မျူလာ က မပြောင်းဘူး။ ဒါ့ကြောင့်မို့ ကိုယ်က သီအိုရီကို ကျွမ်းကျင်ရင် ဒီအသိပညာနဲ့ပတ်သက်တဲ့ ဘယ်အရာကို မဆိုလုပ်ရတာ လွယ်ကူစေတယ်။
“The sad truth is, SQL departs from relational theory in all too many ways; duplicate rows and nulls are two obvious examples, but they’re not the only ones. As a consequence, the language gives you rope to hang yourself with, as it were. So if you don’t want to hang yourself, you need to understand relational theory (what it is and why); you need to know about”
Terms
SQL အကြောင်းပြောကြတဲ့အခါ ကျွန်တော်တို့ သုံးနှုံးတဲ့ စကားလုံးတွေကို ရောချမိတာများတယ်။ ဉပမာ row နဲ့ tuple ဆိုတာ တူတူပဲ ဆိုတာမျိုး အယူအဆမှားတတ်တယ်။ဆင်တူသယောင်ယောင်နဲ့ တကယ်တန်းက ခြားနားမှုတွေရှိတယ်။ အဓိကကတော့ သီအိုရီအသုံးအနှုန်း နဲ့ SQL အသုံးအနှုန်း လို့ မှတ်လို့ရတယ်။ SQL က သီအိုရီအသုံးအနှုန်းတွေကို မသုံးထားဘူး။ ဉပမာ
- SQL မှာ Table, Relational Theory မှာ Relation နဲ့ Relvar
- SQL မှာ Row, Theory ထဲမှာ Tuple
- SQL မှာ Column, Theory ကျတော့ာ Attribute
လို့ အကြမ်းဖြင်း သိထားလို့ရတယ်။
Model မှာ ကျွန်တော်တို့က Database အထဲ Relations တွေကိုသိမ်းတယ်လို့မြင်တယ်။ Relations ဆိုတာက n-dimenson ရှိတဲ့ space တစ်ခုလို့မြင်ကြည့်လို့ရတယ်။ သူ့မှာ Attribute ၅ ခု ရှိရင် 5-dimenson, ၁၀ ခုရှိရင် 10-dimenson လို့ပြောတယ်။ Relational မှာ Relvar (Relation Variable) တွေရှိတယ်။
Relation & Relvar
Relvar(Relation Variable) ဆိုတာက ကျွန်တော်တို့ programming က variable လိုပဲ သူက Relation တစ်ခုကို လက်ခံထားတဲ့ variable တစ်ခုလို့ပြောလို့ရတယ်။ Relation ကမှ တကယ်သိမ်းထားတဲ့ value တစ်ခုလို့ မြင်ကြည့်လိုရတယ်။ မြင်အောင်ပြမယ်ဆိုရင်
int a = 2
a ဆိုတာက variable, သူ့ထဲမှာ ဝင်လာမဲ့ value က ‘2’။ ဒီလိုပဲ student relation တစ်ခုရှိမယ်ဆိုရင် ‘student’ ဆိုတာက relvar ဖြစ်နေမယ်၊ သူထဲမှာဝင်လာမဲ့ ID တွေ, name အတွဲတွေပေါင်းထားတာက relation ဖြစ်မယ်။ SQL မှာကျတော့ ဒီ concept တစ်ခုလုံးပျောက်သွားပြီး table ဆိုတာပဲရှိတော့တယ်။ Table နာမည်ပေးလို့ရသေးတော့ table နာမည်ကိုပဲ relvar အဖြစ်ယူဆလို့လဲရတယ်။
Attribute
Attribute တွေက Relvar တစ်ခုရဲ့ type (တကယ်တမ်း က domain လို့ခေါ်တယ်။ တူတူပဲလို့တော့ CJ Date ကပြောတယ်) လို့ပြောလို့ရတယ်။ သူ့မှာ နှစ်မျိုးရှိမယ်၊ System type နဲ့ user-defined type။ ဉပမာ System Type ဆိုတာ ပုံမှန် integer,char, boolean အစရှိသဖြင့်ပေါ့။ Domain ဆိုတာ ဆိုကြပါဆို့၊ ပိုက်ဆံဆိုရင် နောက်က “ကျပ်”နဲ့ ဆုံးရမယ်၊ ပိုက်ဆံနှစ်ခုကို ပေါင်းလို့ရမယ်၊ နှုတ်လို့ရမယ်။ မြှောက်လို့၊ စားလို့မရဘူး။ ဒါပေမဲ့ ကိန်းဂဏန်းဆိုတဲ့ type နဲ့ မြှောက်ရင်/စားရင် တော့ “ပိုက်ဆံ” type ပဲပြန်ထွက်ရမယ်။ ဒီလိုမျိုး attribute တွေမှာ သတ်မှတ်ထားတဲ့ စည်းမျဉ်းတွေရှိတယ်။ SQL implementation တော်တော်များများက user-defined type တွေလုပ်လို့မရဘူး။ PostgreSQL မှာတော့ ရတယ်ကြားဖူးတယ်။ တကယ်တမ်းကတော့ ဒီလောက်ထိလုပ်ဖို့ဆိုတာ တော်တော်ရှားတဲ့ case လို့တော့ဆိုထားတယ်
Thus, any system that provides proper type support — and “proper type support” here certainly includes the ability for users to define their own types — must provide a way for users to define their own operators, too, because types without operators are useless.
မြင်သွားအောင် Student Relations တစ်ခုကိုမြင်ကြည့်မယ်ဗျာ။ Student Name, Course ID ဆိုပြီးရှိမယ်ဆိုပါဆို့။ Course Relations မှာဆိုလည် Course ID နဲ့ Course Name ဆိုပြီးရှိမယ်။
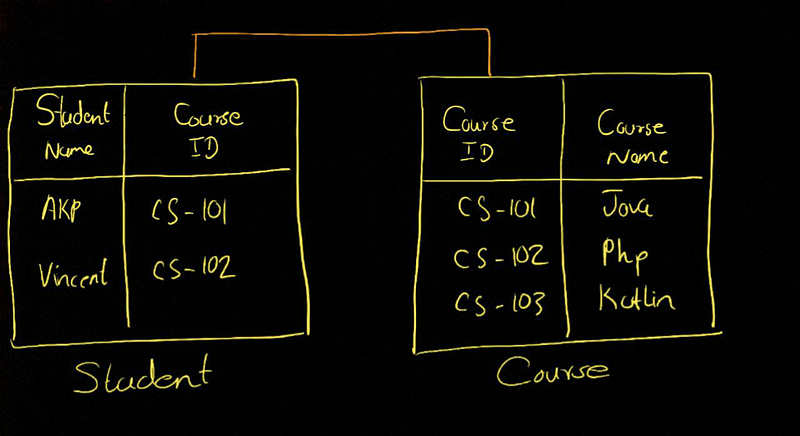
ဒီမှာ user-defined type (domain) က နှစ်မျိုးရှိမယ်။ Name type နဲ့ Course ID ဆိုပြီးဖြစ်မယ်။ ဒါကိုမှ ခွဲချင်သေးရင် သုံးခုခွဲလို့ရတယ်; Student Name , Course ID, Course Name ဆိုပြီး user-defined type (domain) ဖြစ်မယ်။ ဒီမှာကျွန်တော် char တွေ int တွေမပြောပဲ domain တစ်ခုလို့မြင်ကြည့်မယ်။ ဒီမှာ ကျွန်တော်တို့ Student.CourseID နဲ့ Course.CourseID နှစ်ခု equal ချမယ်ဆို တူလား မတူလားစစ်ခွင့်ရှိတယ်။ သို့သော် Student.StudentName နဲ့ Course.CourseName က domain တစ်ခုတည်းမဟုတ်လို့ equal ချလို့ မရ ရဘူး။ သူ့ဟာသူ “ABC” char နဲ့ “ABC” char သွားတူနေလည်း ရကိုမရ ရဘူး။ ဒါပေမဲ့ SQL မှာ ဒါမျိုးတွေမရှိဘူး။ value နှစ်ခုက domain တစ်ခုတည်းက မဟုတ်လည်း JOIN တွေ equal တွေလုပ်လို့ရတယ်။
Note: One thing SQL’s domains most definitely don’t do is constrain comparisons. For example, suppose columns S.CITY and P.CITY are defined on SQL domains SCD and PCD, respectively. Then you might expect the comparison S.CITY = P.CITY to fail.
Tuple
Tuple ဆိုတာကတော့ SQL ကို ရောက်တဲ့အချိန်မှာ row ဆိုပြီးဖြစ်သွားတယ်။ သင်္ချာအမြင် မှာဆိုရင်တော့ အစု(sets) တစ်ခုလို့မြင်လို့ရတယ်။ အစု ဆိုတဲ့အတိုင်း သူ့မှာ အစုတွေမှာ ရှိသင့်တဲ့ ဂုဏ်သတ္တိတွေရှိတယ်။ ဉပမာ ပြောရမယ်ဆို သင်္ချာမှာ {1,2,3} နဲ့ {2,3,1} ကတူညီတယ်။ အစဉ်တိုင်းလာစရာမလိုဘူး။ Relational Model အနေနဲ့ကြည့်မယ်ဆို {"Aung Aung", "Mathematics", "Univeristy of Yangon"} နဲ့ { "Mathematics", "Univeristy of Yangon", "Aung Aung"} က တူတူပဲ။ ရှေ့နောက်ညီစရာမလိုဘူး။ဒါပေမဲ့ SQL ရောက်သွားတဲ့အချိန်မှာ ရှေ့နောက် အစီအစဉ်တွေက စကားပြောလာတယ်။ {1,2,3} နဲ့ {2,3,1} ကို SQL ရဲ့ equal operator ထဲထည့်လိုက်ရင် မတူဘူး(false) ဆိုပြီး ပြောနေမယ်။
This property follows because, again, a body is defined to be a set, and sets in mathematics have no ordering to their elements (thus, for example, {a,b,c} and {c,a,b} are the same set in mathematics,
Duplication
နောက်တစ်ချက်က Relation တစ်ခုမှာ tuple နှစ်ခုဘယ်တော့မှ မထပ်ဘူး။ ပြောချင်တာက {1,2,3} လာပြီးရင် နောက်ထပ် {1,2,3} ထပ်လာလို့မရဘူး။ ဘာလို့လဲဆိုရင် ကျွန်တော်တို့က tuple တွေကို set လို့ယူဆသလိုမျိုး relation တွေကလည်း တကယ်တော့ tuple set တွေပါပဲ။ ပြောရရင်
relation R = { {"Aung Aung", "Mathematics", "Univeristy of Yangon"}, {"Kyaw Kyaw", "Biology", "University of Mandalay"}}လို့သတ်မှတ်လို့ရတယ်။ ဒီတော့ set တွေရဲ့ ဂုဏ်သတ္တိအရ တူတဲ့ အရာနှစ်ခုပါလို့မရဘူး။
A set is a collection of well defined and distinct objects.
ဒါပေမဲ့ SQL မှာ ကိုယ်က သေချာ DISTINCT မထည့်ထားရင် တူညီတဲ့ row နှစ်ခုကို နှစ်ခါထည့်လို့ရနေမယ်။ ဒီတော့ SELECT DISINCT ထည့်ခေါ်တာမျိုးလုပ်သင့်တယ်။
Relations never contain duplicate tuples. This property follows because a body is defined to be a set of tuples, and sets in mathematics don’t contain duplicate elements. Now, SQL fails here, as I’m sure you know: SQL tables are allowed to contain duplicate rows and thus aren’t relations, in general.
Empty set
Relation တွေကို Tuple set တွေလို့ သတ်မှတ်တယ်။ Tuple တွေကလည်း set တွေပဲ။ ဒါဆိုရင် set တွေမှာ နောက်ထပ်ရှိတဲ့ ဂုဏ်သတ္တိ က empty set ဆိုတာ set တိုင်းရဲ့ subset ဖြစ်တယ်။
Now, as I’m sure you know, the empty set — i.e., the set that contains no elements — is a subset of every set. It follows that the empty heading is a valid heading! — and hence that a tuple with an empty set of components is a valid tuple
Empty set Relation နှစ်မျိုးပဲ ဖြစ်နိုင်တယ်။ ပထမတစ်ခုက ဘာ attribute မှမရှိ၊ ဘာ tuple မှ မရှိတဲ့ Relation။ ဒုတိယတစ်ခုက empty tuple တစ်ခုရှိတဲ့ relation။ Empty tuple တစ်ခုရှိပြီးရင် duplication rule အရ နောက်တစ်ခုထပ်ရှိလို့မရဘူး။ ဒီတော့ empty tuple တစ်ခုရှိတဲ့ relation၊ ဘာမှကို မရှိတဲ့ relation လို့ပြောလိုရတယ်။ ဒါတွေက အရေးကြီးလို့လား ဆိုတော့ SQL မှာတော့ မဟုတ်ပေမဲ့ Relational Model မှာ အရေးပါတယ်။ ဘယ်လိုအရေးပါလဲဆိုတာ မြင်အောင်ပြောရရင် သင်္ချာမှာ “သုည” အရေးပါသလို ပဲ။ (ရိုမန်တွေက သုံးညမရှိပဲ အဆင်ပြေအောင် ကြိုးစားဖူးတယ်၊ လုပ်တဲ့အခါမှာလည်း သူတို့တွေ ခေါင်းတွေကို နောက်ကုန်ရော)ဒီမှာတော့ ရေးရင် အရှည်ကြီးဖြစ်သွားမှာမလို့ မရေးတော့ဘူး။ မတူတာလေးကိုပဲမြင်စေချင်တာ၊ SQL မှာက empty set ဆိုတဲ့ ဂုဏ်သတ္တိလုံးဝ မရှိဘူး။ အဲဒီအစား null ဆိုတဲ့ အရာဖြစ်လာတယ်။ NULL ပြဿနာက developer တိုင်းနီးပါး ကြုံဖူးမှာပါ။ (null နဲ့ empty set လုံးဝမတူ၊ 0 က NULL မဟုတ်)
Nullability
Nullability အကြောင်းပြောမယ်ဆိုလို့ တကယ်တမ်းက relation မှာ NULL ဆိုတာ လုံးဝကို မရှိဘူး။ ဘာလို့မရှိတာလဲဆိုရင် relation တွေက “truth proposition” (မှန်ကန်သော အဆိုပြုချုက်) ကိုအခြေခံတယ်။ ပြောချင်တာက Student Relation တစ်ခုကို မြင်ကြည့်ကြမယ်။

ဒီမှာ ရှိတဲ့ Attribute တွေက ID,Name,Age,Township ဆိုပြီးရှိမယ်။ ပထမ relvar ရဲ့ အဆိုပြုချက်က “ကမာရွတ်မြို့နယ်တွင်နေသော ဗင်းဆင့် ဟူသော နာမည်ရှိသည့် ကျောင်းသားသည် ကျောင်းဝင်အမှတ် 1-CS-20 ရှိပြီး အသက်မှာ ၁၇ နှစ်ရှိသည်။” ဖြစ်မယ်။ ဒါ့ကို ကျွန်တော်တို့က မှန်ကန်သော အဆိုပြုချက် လို့ခေါ်မယ်။
Indeed, it was Codd’s very great insight, when he invented the relational model back in 1969, that a database, despite the name, isn’t really just a collection of data; rather, it’s a collection of facts, or in other words true propositions.
ဒီမှာထူးဆန်းတာက ဗင်းဆင့်က NULL အသက်ရှိလို့ ရလို့ကို မရဘူး။ “ငါ့အသက်ကတော့ NULL ကွ” ဆိုပြီးလည်း အပြင်မှာ ဘယ်သူ့မှမပြောဘူး။ အပြင်လက်တွေ့တကယ်မရှိတဲ့ မြို့နယ်မှာနေလို့မရဘူး။တကယ်မရှိတဲ့ အသက်လည်း မဖြစ်နိုင်ဘူူး။ တကယ်မရှိတဲ့အရာက အမှန်တရားတစ်ခုဖြစ်လာလို့မရဘူး။ ဒီတော့ Relational ကျချင်ရင် SQL ရဲ့ column တိုင်းကို NON NULL ပေးရတယ်။
ဒီလို NON NULL ပေးတာက performance အရကြည့်ရင်လည်း ပိုကောင်းတယ်။ SQL implementation တော်တော်များများမှာ “optimizer” ဆိုတာပါတယ်။ Optimizer ရဲ့အလုပ်လုပ်ပုံက သင်ရေးလိုက်တဲ့ query (Q1) ကို ပိုမြန်တဲ့ query နောက်တစ်ခု (Q2) ဖြစ်အောင်ပြောင်းပေးတယ်။ တကယ်လို့ သင့် column တွေက NON NULL ဖြစ်ခဲ့မယ်ဆိုရင် optimizer က ပိုအဆင်ပြေ၊ ပိုမြန်တဲ့ query တွေအဖြစ်ပြောင်းပေးနိုင်တယ်။
ဒီလောက်ဆိုရင် SQL က Relational database အပြည့်အဝမဟုတ်ဘူးဆိုတာတော့သိသွားလောက်ပြီ။ ဒီမှာ မရေးထားတဲ့ တစ်ခြား ကွဲပြားတဲ့ အချက်တွေအများကြီးရှိသေးတယ်။ စိတ်ဝင်စားဖို့ ကောင်းမဲ့ အရာလေးတွေတော့ ကောက်နှုတ်ထားတယ်။ တကယ့်လို့စိတ်ဝင်စားရင် “SQL and Relational Theory” ကို ရှာဖတ်ကြည့်ဖို့ အကြံပေးလိုပါတယ်။ ဖတ်ကြည့်မှလည်း တကယ့်ကို SQL ကိုထဲထဲဝင်ဝင် နားလည်လာလိမ့်မယ်။ မှားတာရှိရင်လည်း ပြင်ပေးကြပါဦိး။